如何构建高可用性系统?[译]
Categories: translates
原文:How do We Design for High Availability?
如何构建高可用性系统?
在数字存在对商业连续性至关重要的今天,高可用性(HA)已经成为系统设计的关键要素。所谓高可用性,是指系统能够在较长时间内持续不间断地运行。
本篇文章将带你深入了解高可用性的发展历程、衡量方法、在各式系统中的实施策略,以及为之付出的各种取舍。
什么是高可用性?
高可用性的理念起源于20世纪60年代和70年代,当时的军用和金融计算系统追求的是高度的可靠性和容错能力。
进入互联网时代,随着电商、支付、物流、金融等数字应用的迅猛发展,优质的用户体验已成为商业成功的关键。因此,商业系统需要接近100%的在线时间,以避免短暂的故障就丢失大量用户。例如,在一个限时抢购活动中,一分钟的系统停机都有可能导致活动失败,给企业声誉带来巨大损害。
高可用性的目的是让系统或服务在接近100%的时间内始终处于可用和正常运行状态。虽然高可用性和系统在线时间这两个概念常常混用,但高可用性的含义远不止于对在线时间的度量。
我们如何测量高可用性?
计算可用性离不开两个核心概念:平均无故障时间(MTBF)和平均修复时间(MTTR)。
MTBF 和 MTTR
MTBF 是通过将系统的运行时间总和除以该时间段内的故障次数来评估系统可靠性的,一般用小时表示。MTBF 越高,表明系统可靠性越好。
MTTR 则是修复一个失败的组件或系统并使其重新运行所需的平均时间。它包括诊断、获取备件、实际修复、测试及确认运行等所需时间。MTTR 也通常使用小时来衡量。
如下图所示,除了 MTBF 和 MTTR,还有两个相关的指标 - 平均诊断时间(MTTD)和平均故障时间(MTTF),而MTTR也可以包括诊断时间。

九级标准
结合MTBF和MTTR,我们可以计算出系统的可用性,即系统运行时间与总时间和维修时间之和的比例,公式如下:
可用性 = MTBF /(MTBF + MTTR)
对于追求高可用性的系统,目的是让MTBF最大化(减少故障次数)和MTTR最小化(快速恢复故障)。这些指标是团队提升系统可靠性和可用性的重要依据。
如下图所示,我们通常按照“九级”来讨论可用性。比如“3个九”的可用性意味着每天仅有1.44分钟的停机时间,这对手动排错来说是个挑战。“4个九”则意味着每天仅8.6秒的停机,这就需要自动化监控、警报和故障排除。因此,系统设计时要考虑到自动故障检测和回滚计划等要求。

常见的架构模式
想要实现“4个九”或更高级别的可用性,我们需要考虑下面几点:
- 系统设计要点
- 考虑到失败的冗余设计
- 需要做的取舍
- 系统运维
- 变更管理
- 容量管理
- 自动化检测与故障排除
下面我们来详细看看系统设计方面的内容。
冗余
优化单一实例的容错性是有限的。通常,通过增加冗余来实现高可用性。当一个实例出现问题时,其他实例可以立刻接手继续工作。
对于像存储这样需要保持状态的实例,还需要考虑数据复制的策略。
接下来我们介绍几种包含不同冗余方式的常见架构,及其各自的优缺点。
热-冷架构
在热-冷架构中,有一个主实例负责处理所有的读写请求,外加一个备份实例。客户端只与主实例进行交互,对于备份实例则完全无觉。主实例会持续地同步数据至备份实例。若主实例出现问题,就需要手动介入,将客户端切换至备份实例。
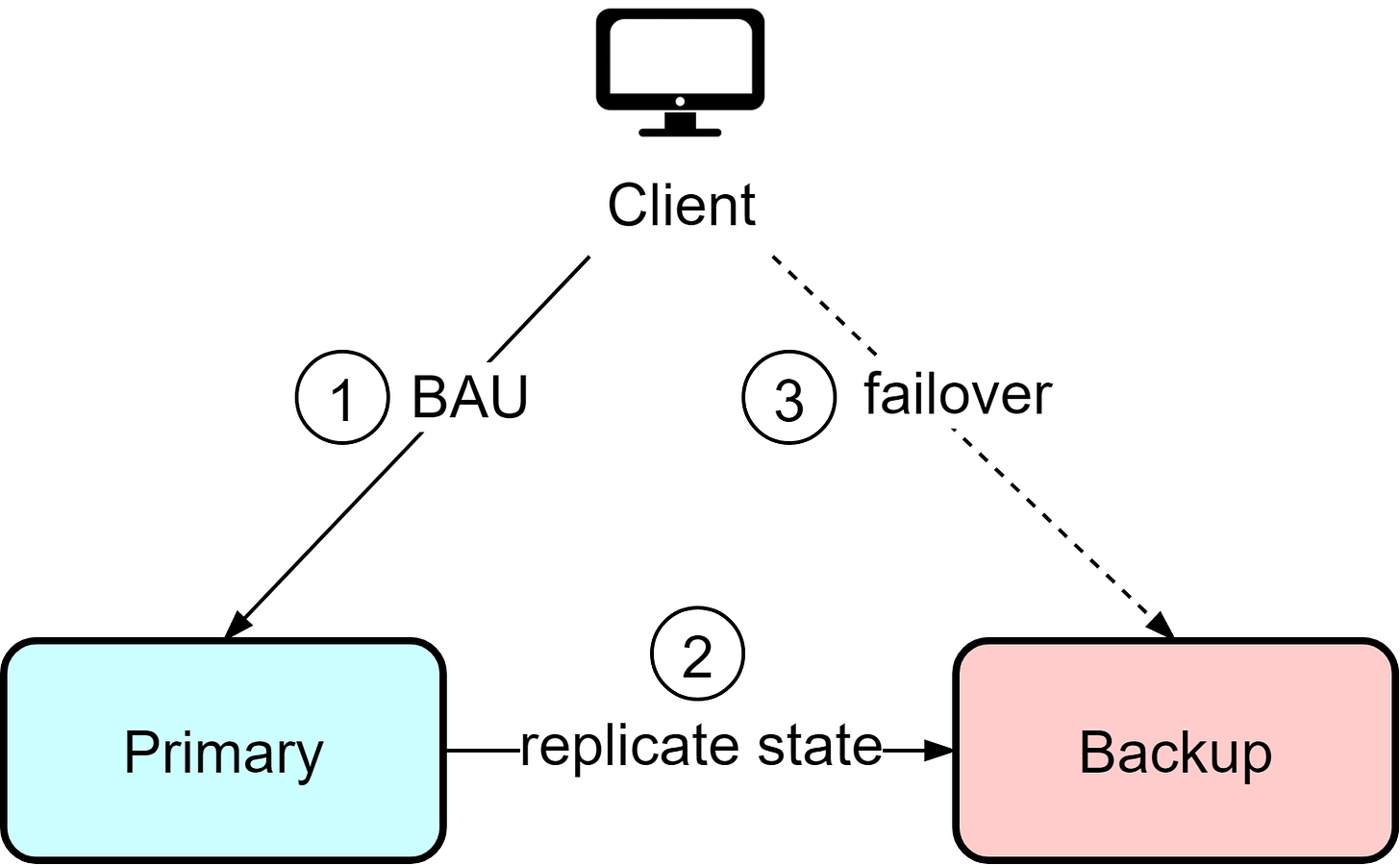
这种架构虽然简单,但有不小的弊端。备份实例在大多数时间内处于闲置状态,这就造成了资源的浪费。如果主实例出现故障,最后一次数据同步的时间将决定是否会有数据丢失。在备份实例上恢复服务时,需要手动核对当前状态,以确认哪些数据可能丢失了,这意味着客户端可能需要重新发送遗失的信息,以弥补数据的丢失。
热-温模式
热-冷模式中的备份实例没有得到充分使用,导致资源被浪费。热-温模式通过允许客户端从备用实例读取数据来解决这一问题。如果主实例出现故障,客户端还能从下线的备用实例读取数据,虽然性能会稍有下降。
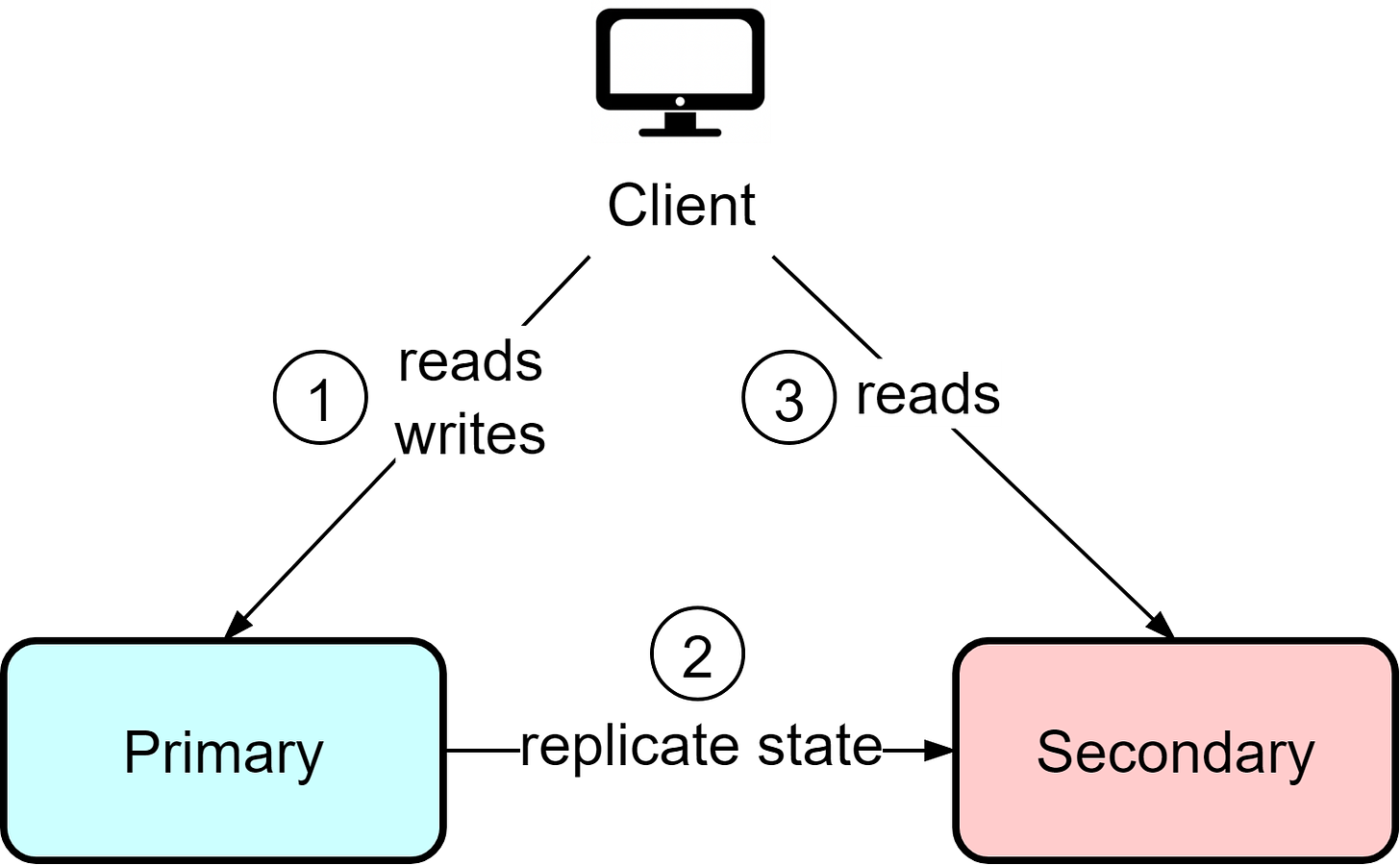
由于备用实例也参与数据读取,因此主备实例之间保持数据一致性就显得尤为重要。哪怕主实例运作正常,由于读取操作同时对两个实例发起,也可能读到旧的数据。
相较于热-冷模式,热-温模式更适合于读操作较多的场景,如新闻网站和博客。不过,为了更有效地使用资源,即使系统运行正常,也可能会读到过时的数据。
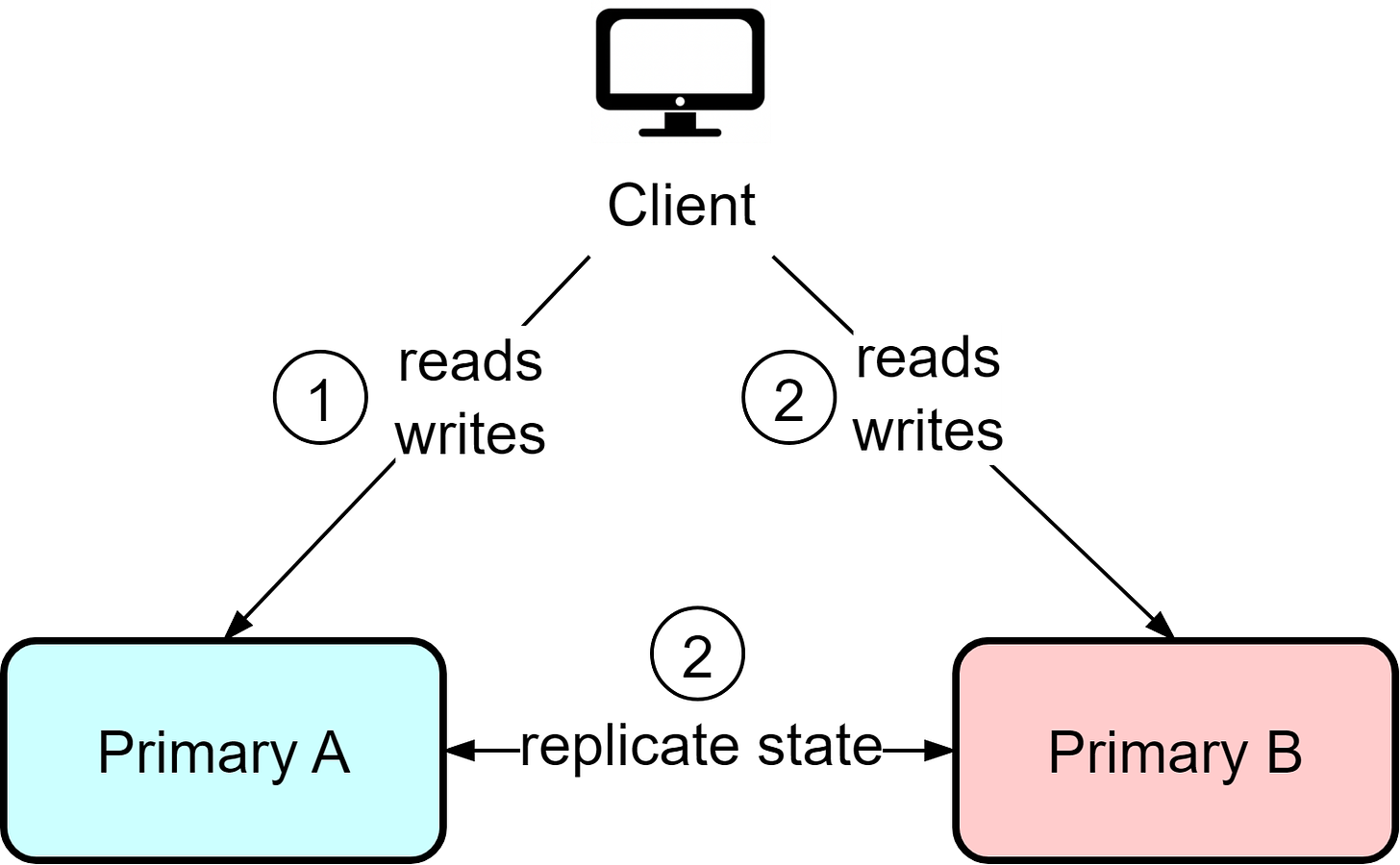
热-热模式
在热-热模式下,两个实例都作为主实例,均可处理读写请求。这种模式带来了极大的灵活性,但同时也意味着需要在两个实例之间进行双向同步。某些需要严格顺序性的数据可能会因此发生冲突。
比如,假设系统按顺序分配用户ID,Bob可能在实例A得到ID 10,而Alice可能同样在实例B得到ID 10。热-热模式在需要复制的数据量较小时最为有效,常见于涉及临时数据的场景,如用户的会话和活动。对于那些需要严格一致性保障的数据则需要谨慎处理。