构建高级 RAG 的参考指南和方法[译]
Categories: translates
原文:A Cheat Sheet and Some Recipes For Building Advanced RAG
作者:Andrei
新的一年开始了,也许你打算正式步入 RAG 领域,创建你的第一个 RAG 系统。又或者,你已经打造过初级的 RAG 系统,现在希望将它们升级,以便更好地处理用户的查询和数据。
无论是哪种情况,你可能都会面临一个难题:到底怎么开始呢?如果你有此困扰,那么这篇博客文章或许能为你指明方向,进一步的,当你创建高级 RAG 系统时,它能为你提供一个思考的框架。
上面分享的 RAG 指南,在很大程度上是受到了一篇最近的 RAG 调研文章的启发(“Retrieval-Augmented Generation for Large Language Models: A Survey” Gao, Yunfan, et al. 2023)。
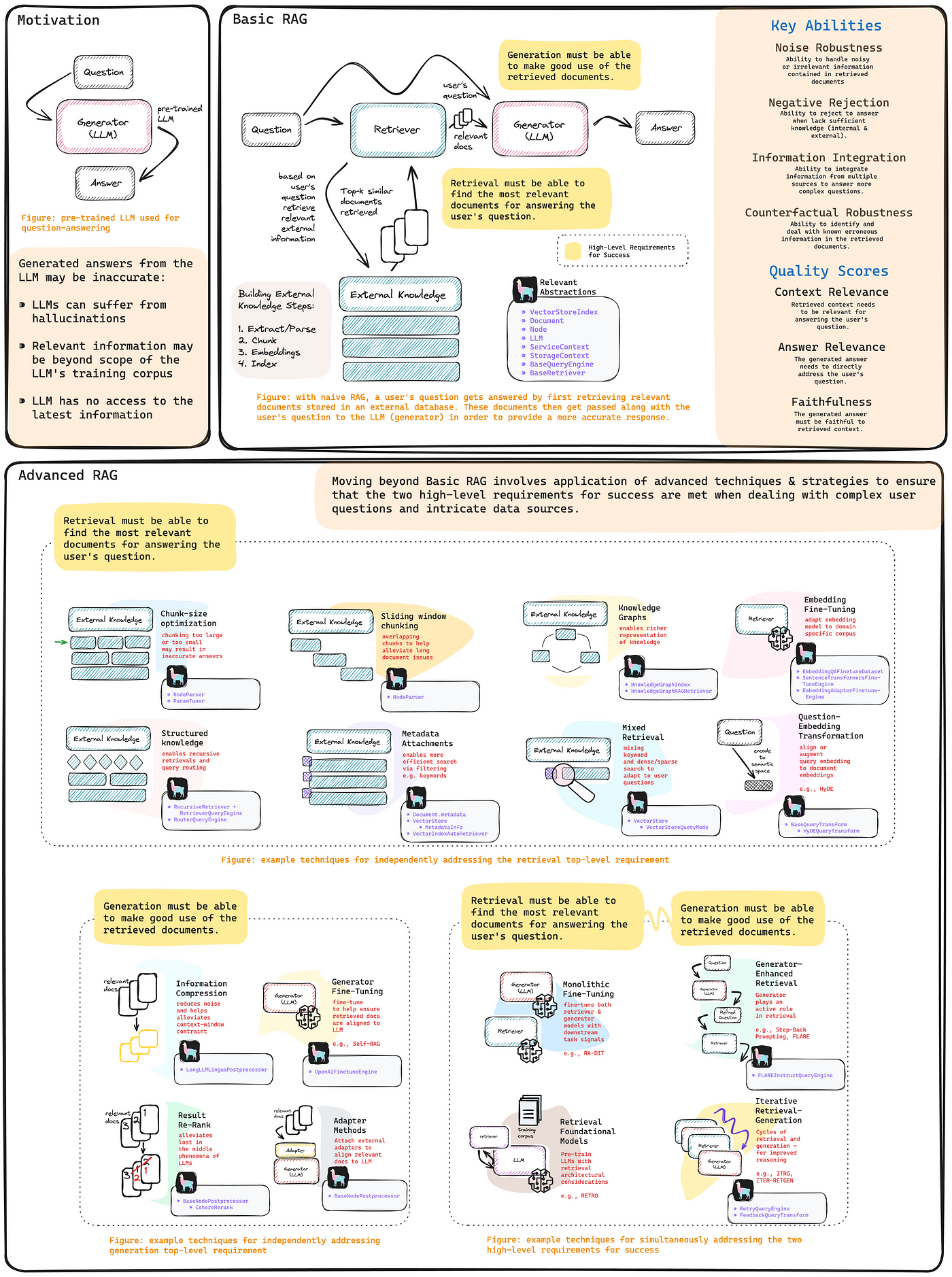
初级 RAG
目前的主流 RAG 定义,涉及从外部知识库中检索文档,并将这些文档与用户的查询一同提交给大语言模型生成回复。也就是说,RAG 包括检索、外部知识库和生成三个部分。
LlamaIndex 初级 RAG 方法:
from llama_index import SimpleDirectoryReader, VectorStoreIndex
# load data
documents = SimpleDirectoryReader(input_dir="...").load_data()
# build VectorStoreIndex that takes care of chunking documents
# and encoding chunks to embeddings for future retrieval
index = VectorStoreIndex.from_documents(documents=documents)
# The QueryEngine class is equipped with the generator
# and facilitates the retrieval and generation steps
query_engine = index.as_query_engine()
# Use your Default RAG
response = query_engine.query("A user's query")
RAG系统成功的标准
要判断一个RAG系统是否成功(在为用户问题提供有用和相关答案方面),其实只需要满足两个关键性的需求:
- 在执行搜索时,必须能够找到与用户问题最相关的文件。
- 在进行信息构造时,必须能够充分利用搜索到的文件来对用户的问题进行有效的回答。
高级RAG
定义了成功的标准后,我们就可以明白,建立高级的RAG实际上就是要运用更复杂的技术和策略(主要应用到搜索或是信息构造阶段),以确保最终能满足这些需求。进一步说,我们可以把复杂的技术分为两大类,一类是能够独立满足任一成功标准的,另一类则是能够同时满足这两个标准的。
高级的搜索技术必须能找到与用户问题最相关的文件
接下来我们简要介绍一些较为复杂的技术,帮助实现第一个成功标准。
- 数据块大小优化:由于大型语言模型受到上下文长度的限制,构建外部知识库时必须要对文件进行分块。如果块的大小过大或过小,都会对信息构造工作造成困扰,从而导致输出的答案不准确。
LlamaIndex数据块大小优化方法(notebook 指南):
from llama_index import ServiceContext
from llama_index.param_tuner.base import ParamTuner, RunResult
from llama_index.evaluation import SemanticSimilarityEvaluator, BatchEvalRunner
### Recipe
### Perform hyperparameter tuning as in traditional ML via grid-search
### 1. Define an objective function that ranks different parameter combos
### 2. Build ParamTuner object
### 3. Execute hyperparameter tuning with ParamTuner.tune()
# 1. Define objective function
def objective_function(params_dict):
chunk_size = params_dict["chunk_size"]
docs = params_dict["docs"]
top_k = params_dict["top_k"]
eval_qs = params_dict["eval_qs"]
ref_response_strs = params_dict["ref_response_strs"]
# build RAG pipeline
index = _build_index(chunk_size, docs) # helper function not shown here
query_engine = index.as_query_engine(similarity_top_k=top_k)
# perform inference with RAG pipeline on a provided questions `eval_qs`
pred_response_objs = get_responses(
eval_qs, query_engine, show_progress=True
)
# perform evaluations of predictions by comparing them to reference
# responses `ref_response_strs`
evaluator = SemanticSimilarityEvaluator(...)
eval_batch_runner = BatchEvalRunner(
{"semantic_similarity": evaluator}, workers=2, show_progress=True
)
eval_results = eval_batch_runner.evaluate_responses(
eval_qs, responses=pred_response_objs, reference=ref_response_strs
)
# get semantic similarity metric
mean_score = np.array(
[r.score for r in eval_results["semantic_similarity"]]
).mean()
return RunResult(score=mean_score, params=params_dict)
# 2. Build ParamTuner object
param_dict = {"chunk_size": [256, 512, 1024]} # params/values to search over
fixed_param_dict = { # fixed hyperparams
"top_k": 2,
"docs": docs,
"eval_qs": eval_qs[:10],
"ref_response_strs": ref_response_strs[:10],
}
param_tuner = ParamTuner(
param_fn=objective_function,
param_dict=param_dict,
fixed_param_dict=fixed_param_dict,
show_progress=True,
)
# 3. Execute hyperparameter search
results = param_tuner.tune()
best_result = results.best_run_result
best_chunk_size = results.best_run_result.params["chunk_size"]
2. 结构化的外部知识: 在复杂的场景中,仅仅依靠基本的向量索引构建外部知识可能是不够的,我们可能需要增加一些结构性的元素,以实现递归检索或者针对明显区分开的外部知识源采用路由式检索。
LlamaIndex 递归检索步骤 (notebook 指南):
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.schema import IndexNode
### Recipe
### Build a recursive retriever that retrieves using small chunks
### but passes associated larger chunks to the generation stage
# load data
documents = SimpleDirectoryReader(
input_file="some_data_path/llama2.pdf"
).load_data()
# build parent chunks via NodeParser
node_parser = SentenceSplitter(chunk_size=1024)
base_nodes = node_parser.get_nodes_from_documents(documents)
# define smaller child chunks
sub_chunk_sizes = [256, 512]
sub_node_parsers = [
SentenceSplitter(chunk_size=c, chunk_overlap=20) for c in sub_chunk_sizes
]
all_nodes = []
for base_node in base_nodes:
for n in sub_node_parsers:
sub_nodes = n.get_nodes_from_documents([base_node])
sub_inodes = [
IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes
]
all_nodes.extend(sub_inodes)
# also add original node to node
original_node = IndexNode.from_text_node(base_node, base_node.node_id)
all_nodes.append(original_node)
# define a VectorStoreIndex with all of the nodes
vector_index_chunk = VectorStoreIndex(
all_nodes, service_context=service_context
)
vector_retriever_chunk = vector_index_chunk.as_retriever(similarity_top_k=2)
# build RecursiveRetriever
all_nodes_dict = {n.node_id: n for n in all_nodes}
retriever_chunk = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever_chunk},
node_dict=all_nodes_dict,
verbose=True,
)
# build RetrieverQueryEngine using recursive_retriever
query_engine_chunk = RetrieverQueryEngine.from_args(
retriever_chunk, service_context=service_context
)
# perform inference with advanced RAG (i.e. query engine)
response = query_engine_chunk.query(
"Can you tell me about the key concepts for safety finetuning"
)
其他有用的链接
我们有数个指南,展示了如何利用其他高级技巧,在复杂的情境中精确地检索信息。以下是我们推荐的一些链接:
高级生成技术应能善于利用已检索到的文档
这部分的内容与前述部分有些类似,我们同样提供了一些复杂技术的实例,其总体目标是要确保检索到的文档与大语言模型(LLM)的生成器能够良好对接。
- 信息压缩: 大语言模型(LLM)的处理上下文长度是有限的,如果检索到的文档中含有过多的噪声(比如:无关的信息),可能会导致响应质量下降。
LlamaIndex 信息压缩步骤 (notebook 指南):
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import LongLLMLinguaPostprocessor
### Recipe
### Define a Postprocessor object, here LongLLMLinguaPostprocessor
### Build QueryEngine that uses this Postprocessor on retrieved docs
# Define Postprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder
},
)
# Define VectorStoreIndex
documents = SimpleDirectoryReader(input_dir="...").load_data()
index = VectorStoreIndex.from_documents(documents)
# Define QueryEngine
retriever = index.as_retriever(similarity_top_k=2)
retriever_query_engine = RetrieverQueryEngine.from_args(
retriever, node_postprocessors=[node_postprocessor]
)
# Used your advanced RAG
response = retriever_query_engine.query("A user query")
2. 结果重排: 大语言模型(LLM)常常会遭遇所谓的“迷失在中间”现象,也就是模型过于关注语境的两端。因此,在将检索到的文档提交给生成组件前进行一次重新排序,会带来积极的效果。
LlamaIndex 为优化生成效果的重排步骤 (notebook 指南):
import os
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.postprocessor.cohere_rerank import CohereRerank
from llama_index.postprocessor import LongLLMLinguaPostprocessor
### Recipe
### Define a Postprocessor object, here CohereRerank
### Build QueryEngine that uses this Postprocessor on retrieved docs
# Build CohereRerank post retrieval processor
api_key = os.environ["COHERE_API_KEY"]
cohere_rerank = CohereRerank(api_key=api_key, top_n=2)
# Build QueryEngine (RAG) using the post processor
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
index = VectorStoreIndex.from_documents(documents=documents)
query_engine = index.as_query_engine(
similarity_top_k=10,
node_postprocessors=[cohere_rerank],
)
# Use your advanced RAG
response = query_engine.query(
"What did Sam Altman do in this essay?"
)
面向检索和生成要求的先进技巧
在这一节中,我们将探讨一些高级方法,利用检索与生成的协同效益,旨在提高检索效果并得到对用户查询更精准的生成答案。
- 生成器增强型检索: 这些技术充分利用了大语言模型的内在推理能力,在进行检索前精准优化用户查询,直指解答需要的关键信息。
LlamaIndex生成器增强型检索配方(教程指南):
from llama_index.llms import OpenAI
from llama_index.query_engine import FLAREInstructQueryEngine
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
ServiceContext,
)
### Recipe
### Build a FLAREInstructQueryEngine which has the generator LLM play
### a more active role in retrieval by prompting it to elicit retrieval
### instructions on what it needs to answer the user query.
# Build FLAREInstructQueryEngine
documents = SimpleDirectoryReader("./data/paul_graham").load_data()
index = VectorStoreIndex.from_documents(documents)
index_query_engine = index.as_query_engine(similarity_top_k=2)
service_context = ServiceContext.from_defaults(llm=OpenAI(model="gpt-4"))
flare_query_engine = FLAREInstructQueryEngine(
query_engine=index_query_engine,
service_context=service_context,
max_iterations=7,
verbose=True,
)
# Use your advanced RAG
response = flare_query_engine.query(
"Can you tell me about the author's trajectory in the startup world?"
)
2. 迭代型检索-生成器 RAG: 对于一些复杂的问题,我们有时候需要通过多步推理来给出有用且相关的答案。
LlamaIndex迭代型检索-生成器方法 (notebook 指南):
from llama_index.query_engine import RetryQueryEngine
from llama_index.evaluation import RelevancyEvaluator
### Recipe
### Build a RetryQueryEngine which performs retrieval-generation cycles
### until it either achieves a passing evaluation or a max number of
### cycles has been reached
# Build RetryQueryEngine
documents = SimpleDirectoryReader("./data/paul_graham").load_data()
index = VectorStoreIndex.from_documents(documents)
base_query_engine = index.as_query_engine()
query_response_evaluator = RelevancyEvaluator() # evaluator to critique
# retrieval-generation cycles
retry_query_engine = RetryQueryEngine(
base_query_engine, query_response_evaluator
)
# Use your advanced rag
retry_response = retry_query_engine.query("A user query")
RAG的量度考量
对RAG系统进行评估无疑是至关重要的。Gao, Yunfan等人在他们的综述论文中,列出了7个主要的量度因素,可在我们提供的RAG应用方框表的右上方找到。llama-index库包含多个评估抽象和针对RAGAs的集成,以帮助开发者通过这些量度考量,了解他们的RAG系统达成目标的程度。下面,我们列出了部分精选的评估笔记本指南。
你现在已经做好准备,开始RAG的高级应用
阅读了这篇博客文章后,我们期望你能感觉更有自信,更有底气,去采取这些先进技术构建高级的RAG系统!